The Farm Labor Apps You've Been Looking For
Our industry-leading farm labor management apps deliver real time labor and production data directly from the field to the office.
- Easily collect accurate labor and production data from your fields in real time!
- Pay your employees quickly and correctly with minimal effort!
- Month-to-month pricing. No contracts required!
- Quick and easy setup. Get started with your labor management solution today!
![]()
![]()
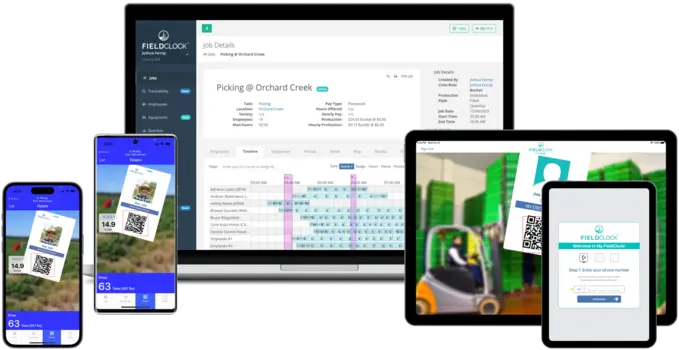
MOBILE APPS
TIME APPS FOR FARMERS
FieldClock & Kiosk
Our apps make farm labor management and data collection simple and effective. FieldClock is designed for the rigors of outdoor work and the technical skills of all users.
It's as easy as pointing a camera!

PAYROLL
DOZENS OF PAYROLL EXPORTS
Easily export payroll to commonly used payroll systems
FieldClock is integrated with over two dozen of the most popular payroll platforms on the market, allowing farmers to export payroll in seconds with the click of a button.
BLOCK-LEVEL ACCOUNTING
POWERFUL REPORTING OPTIONS
Block-level accounting is a breeze with our wide variety of reporting options
EBOOK
Learn how much you're likely to overpay with the old ways
Many farmers think that pen and paper (and punchcards) is the cheapest way to manage their labor. In reality, overpayment and liability are much more expensive than our labor tracking services.
